
Katzentoast – Toast mit Katze? – Katze mit dickem Hals?
Kennen Sie Ihre KI?
Was eine KI kann, und was nicht.
von Adrian Müller
Inhalt
Worum geht es?
Der folgende Beitrag ist eine Langfassung des Vortrags „Verstehen Sie Ihre KI? – Was KI kann, und was nicht.“, gehalten auf der Zukunftsmesse KI 2018.
Der Begriff Künstliche Intelligenz ist zwar in aller Munde, scheint jedoch bei genauerem Nachfragen sehr unterschiedlich besetzt. Ist beispielsweise ein Navigationssystem im Auto intelligent? Ist es „mehr“ intelligent, wenn es auf Verkehrsstörungen beispielsweise mit einer dynamischen Umfahrung reagiert?
Vor ein, zwei Dekaden wäre ein solches System zumindest technisch gesehen ein kleines Wunderwerk gewesen. Am technischen Fortschritt jedoch kann man einen Begriff inhaltlich nicht festmachen. Erst bei genauerer Betrachtung erkennt man Eigenschaften die unabhängig vom technischen Startpunkt eines Systems oder Lebewesen Gültigkeit haben.
Die Definition von Künstlicher Intelligenz in der Informatik, die sich in vielen Situationen bewährt hat, ist die eines „rationalen Agenten“. Der Agent, ein Computerprogramm, kann eine vorgegebene Aufgabe effizient und zielgerichtet erfüllen. Dabei setzt es je nach Situation und Umgebung Komponenten ein wie automatisches und überwachtes Lernen, Planen unter Zeit und Kostenoptimierung, Mustererkennung in Daten, Bildern, Audio usw.
Diese Komponenten wiederum benutzen Algorithmen zur Datenanalyse, zum Lernen von Mustern, zum logischen Schließen und zum Anwenden von Regeln auf ein gegebenes Problem. Dieser Zusammenhang zwischen Algorithmen, Optimierungen und Anwendungsszenarien wird in der aktuellen Diskussion gerne als „künstliche Intelligenz“ in unangebrachter Weise vereinfacht.
Um ein Beispiel zu geben: die automatische Verschlagwortung eines Bildes ist deutlich weniger intelligent als die Leistung der Saatkrähen im Freizeitpark „Puy de Fou“ im Sommer 2018. Der Falkner des Parks hat sie erfolgreich darauf trainiert, eingesammelte Zigarettenkippen gegen Fressen zu tauschen. Eine intelligente Leistung, die sich nur durch Mustererkennung in Kombination mit zielgerichtetem Lernen erklären lässt (s. Beitrag in Euronews.com, 2018) – und das sehr rational ist!
In diesem „Standpunkt“ fokussieren wir uns auf die Möglichkeiten und Grenzen der Mustererkennung (Bilder, Datensätze), von Lernverfahren, HCI, und Data und Text Mining. Dies entspricht technologisch dem primären Anteil der Systeme, wie sie in den letzten Jahren populär geworden sind. Dazu zählen Foto-tagging Applikationen, Bildmanipulationen, selbstfahrende Autos und Ähnliches.
Eine weiterführende Diskussion zu humanoiden Robotern, autonomen Fahrzeugen und ihrer Zuverlässigkeit, oder beispielsweise medizinischen Expertensystemen vermeiden wir in diesem Beitrag bewusst. Die gesellschaftlichen und ethischen Fragestellungen stellen eine andere Qualität der Diskussion dar.
In diesem Beitrag geht es stattdessen darum, dass sich technische und nicht technische Leser und Zuhörer in ihrem Verständnis von künstlicher Intelligenz gegenseitig kennenlernen können – auf Basis der prinzipiellen Gesetzmäßigkeiten, denen solche Systeme unterliegen.
Was in der aktuellen Diskussion von „KI“ – sprachlich präziser: vom Einsatz der Methoden der künstlichen Intelligenz in der Anwendungsentwicklung – und der allgemeinen Panikmache um die „Gefahr durch eine Super-KI“ und die „Macht der Maschinen“ ebenfalls gerne übersehen wird, sind die kreativen und gestalterischen Möglichkeiten durch den Einsatz einer KI, sei es als Werkzeug, oder als Trainingsgerät und vieles anderes mehr.
Im abschließenden Teil dieses Beitrages finden sich daher kritische Überlegungen zur Mensch-Maschine-Kommunikation genauso wie zu den positiven Auswirkungen von neuen Technologien auf den Erkenntnisgewinn in der Medizin und anderen Bereichen der Forschung. Die assoziierten Schlagwörter hier sind „industrie 4.0“, „high-speed science“, und auch „disruptive“ Technologien.
Mustererkennung vs. Bildverstehen
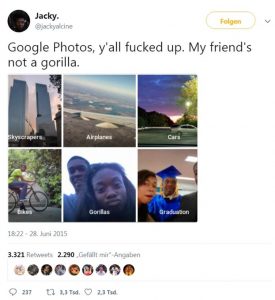
In 2015, a black software developer named Jacky Alciné embarrassed Google by tweeting that the company’s Photos service had labeled photos of him with a black friend as “gorillas.” Google declared itself “appalled and genuinely sorry.” An engineer who became the public face of the clean-up operation said the label gorilla would no longer be applied to groups of images, and that Google was “working on longer-term fixes.”
More than two years later, one of those fixes is erasing gorillas, and some other primates, from the service’s lexicon. The awkward workaround illustrates the difficulties Google and other tech companies face in advancing image-recognition technology, which the companies hope to use in self-driving cars, personal assistants, and other products.
WIRED tested Google Photos using a collection of 40,000 images well-stocked with animals. It performed impressively at finding many creatures, including pandas and poodles. But the service reported “no results” for the search terms “gorilla,” “chimp,” “chimpanzee,” and “monkey.”
Quelle: https://www.wired.com/story/when-it-comes-to-gorillas-google-photos-remains-blind/ Jan.2018
Das gleiche Problem hatte Flickr ebenfalls im Juli 2015. Der kleine Sohn von Sudeepto Bose, von Beruf Schriftsetzer, wurde als „dog“ klassifiziert.
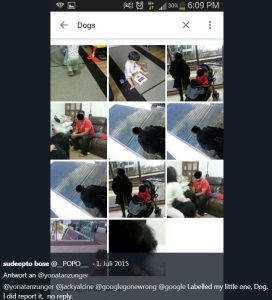
Quelle: twitter.com/yonatanzunger/status/615586630842236928 Herr Zunger hat Google inzwischen verlassen und arbeitet für Humu.
Ähnliche Verwechslungen gab es viele in der Geschichte der automatischen Klassifikation, so wurden Babys und weiße Robben gerne verwechselt. Die Ursachen sind vielschichtig. Die Art und Weise, wie Muster-Erkennungsalgorithmen Bilder betrachten ist fundamental unterschiedlich zur Wahrnehmungen etwa eines Gesichtes durch einen Menschen.
Dies lässt sich durch eine medizinisch beeindruckende Beobachtung erläutern. Ein von Geburt an blinder, verheirateter Mann konnte nach einer Operation wieder sehen. Da er aber die Fähigkeit zum Erkennen von Gesichtern als Kind nie gelernt hatte, konnte auch das Gesicht seiner Frau nicht von anderen Gesichtern unterscheiden. Seine Lösung war es, sich zu merken mit welchen Kleidungsstücken seine Frau morgens die Wohnung verließ, um sie abends daran wieder zu erkennen. Dort lässt sich folgern, dass das menschliche Gehirn Strukturen entwickelt, die bestimmte Funktionsbereiche abdecken.
Die Bilderkennungs-Algorithmen sind typischerweise für unterschiedliche Bildarten gleichermaßen anzuwenden. Trainiert werden sie auf Kombinationen von sogenannten „low level features“: in welchen Regionen des Bildes liegen welche Texturen vor, welche Kanten und Ecken, welche zusammenhängenden Regionen mit welchen Farbeigenschaften usw. Für eine Übersicht siehe https://en.wikipedia.org/wiki/Feature_detection_(computer_vision).
Das Training mit unterschiedlichen Klassifikationen erfordert eine mathematische Optimierung, beispielsweise durch die Gewichte neuronaler Netze, oder die Anwendung von vor Verarbeitungsfiltern. Eine naive Überlegung ist es, dass das Training durch die Zunahme weiterer Features und höhere Trainingsmengen erfolgreicher sein müsste.
Ist das so?
Viele Algorithmen im Data und Text Mining können Muster wie beispielsweise saisonale Einflüsse, Zusammenhänge zwischen Einkaufsverhalten, sozialer Schicht und Marketing Maßnahmen zuverlässig nur bei vorliegenden großen Datenmengen erkennen. Gleichzeitig muss man in einem entsprechenden Projekt die rohen Eingangsdaten interpretieren, glätten, oder auch durch den Einsatz von Filtern gewichten. Der Modebegriff „Big Data“ spiegelt diese Zusammenhänge wieder.
So basiert etwa die Empfehlungsfunktion von Amazon („Kunden die dies gekauft haben, haben auch jenes gekauft“) auf der statistischen Analyse großer, hoch-dimensionaler Matrizen. Hier gilt die Annahme, dass die Vorhersagbarkeit steigt, wenn wir durch die Integration vieler Daten individuelle Fluktuationen beim Verhalten oder ähnlichem ausblenden können. Der Science Slam Beitrag ‚Möchten Sie vielleicht Pommes zu den Pommes?‘ von Johannes Schildgen beim #34 Science Slam Berlin erläutert dies auf eine sehr humorvolle Art und Weise -sehenswert!
Katzentoast – Toast mit Katze? – Katze mit dickem Hals?
Umgekehrt bedeutet die Zunahme neuer Trainingsdaten mit außergewöhnlichen Eigenschaften (wie hier dieses doch recht ungewöhnliche Foto einer Katze mit einer Toastscheibe) eine Herausforderung für ein statistisches Verfahren.
Was soll das System hier lernen:
- Einige Katzen haben Toastscheiben um den Hals?
- Es gibt Toast, das mit Katzen belegt wird?
- Lebewesen können Toastscheiben um den Hals aufweisen?
- Es gibt Menschen mit und ohne Toastscheiben um den Hals?
- Dieses Bild ist eine Ausnahme, die eine Regel (welche eigentlich?) bestätigt?
In der Tat wird ein mathematisches Modell durch die Hinzunahme zusätzlicher Trainingsdaten immer eine bessere Performanz, geringere Fehler erster und zweiter Ordnung aufweisen – jedoch gilt dies in erster Linie nur für die vorliegenden Trainingsdaten und die Validierungsfälle, die bei der Konzeption des Modells in Betracht gezogen wurden
Durch eine sogenannte Kreuzvalidierung muss sich ein System als robust erweisen. Hierzu werden zufällig oder systematisch ausgewählte Daten aus dem Trainingslauf ausgeblendet. Inwieweit die Validierungsdaten homogen mit den Trainingsdaten sind, oder ob sie eine Mischung aus typischen und speziellen Fällen darstellen, entscheiden die Entwickler des Systems. Damit kann sich je nach Bedarf jeder Entwickler seine Erfolg Statistik mehr oder weniger passend gestalten.
Im Beispiel der Google Foto App bedeutet dies, dass später – nach der Konzeption des Lernalgorithmus – aufgenommene Fotos ja von diesem System ebenfalls erkannt werden müssen – und die Entwickler können nur hoffen, dass die inzwischen vorliegenden neuen Bilddaten sich den bisher trainierten Modellen “unterwerfen“.
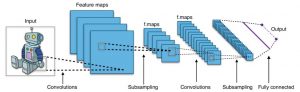
“Convolutionary Neural Networks” (CNNs) – „faltende Netzwerke“ – versprechen einen Ausweg aus diesem Dilemma. Unterschiedliche Filter, wie beispielsweise Schärfung, Glättung, Kantenerkennung, werden überlappend auf Bildregionen angewandt. Das Innovative an diesem Konzept ist, dass die Werte der für die Filter anzuwendenden Matrizen erlernt werden, und überflüssige Filter in einem späteren Verarbeitungsschritt vergessen werden. Das Konzept ist nicht neu, wurde aber früher typischerweise ausschließlich manuell, durch sorgfältiges Design des Systems optimiert. Der Wikipedia Eintrag dazu (https://de.wikipedia.org/wiki/Convolutional_Neural_Network) gibt eine sehr gelungene technische Einführung.
Um die Güte eines Lernverfahrens abzuschätzen verwendet man in der KI und dem Mining sog. ROC Kurven (Receiver-Operating-Characteristic-Kurve). Sie stellt visuell den Zusammenhang und die Abhängigkeit von der Erkennungs-Effizienz und der zugehörigen Fehlerrate für verschiedene Algorithmen oder Parameter dar. Eine einfache Sichtweise ist es, dass jeweils zu vergleichende System zuerst mit den Dingen zu befragen, die es besonders gut kann. Wie stark später die Kurve bei den schwierigeren Beispielen abflacht ist ein Indiz für die Güte und die Robustheit des Systems. Insgesamt lässt sich die totale Fehlerquote als Fläche unter der Kurve interpretieren. Die Hauptdiagonale von unten links nach oben rechts entspricht einem reinen Raten für jedes zu klassifizierende „Ding“.
Hier eine aktuelle Studie, in der unterschiedliche Lernverfahren kontrastiv verglichen wurden an einem konkreten Beispiel:
Driven by the desire for a better user experience and enabled by improved data storage and processing, [..] we propose a data-driven resource allocation framework that uses data-generated prediction models to explicitly guide resource allocation for user experience improvement. […] Our approach consists of three components: we train a logistic regression classifier to predict user experience, utilize the trained likelihood as the objective function to allocate network resource, and then evaluate user experience with allocated resource to (in)validate and adjust the original model. We design a DualHet algorithm to tackle the problem of multi-dimensional resource optimization with heterogeneous users. Numerical simulations based on both synthetic and real network data sets demonstrate the effectiveness of the proposed algorithms. In particular, the simulations based on real data demonstrate up to 2× performance improvement compared with the baseline algorithm
.
Quelle: From Prediction to Action: Improving User Experience with Data-Driven Resource Allocation, in EEE Journal on Selected Areas in Communications PP(99):1-1 · March 2017 ith 26 Reads, DOI: 10.1109/JSAC.2017.2680918
Und die rechts stehende Auswertung ergab: die Neuronalen Netze waren gut – aber nicht der beste Algorithmus für dieses Problem.
Verstehen Sie Siri?
Der Arbeitskreis Smart Machines der Hochschule Kaiserslautern präsentierte auf der CeBIT 2018 eine Umfrage zu sprach-basierten Assistenzsystemen. Weitere Exponate finden Sie in unserem Blog zur CEBIT. Ziel der Umfrage war es, das Verständnis der Messebesucher von Alexa und dem Google Assistenten zu überprüfen. Die Fragen an Alexa und den Google Assistent überdecken wichtige Bereiche des menschlichen Sprachverständnisses – Syntax, Semantik, Gesprächsführung, Intonation, Pragmatik, Semiotik, Referenzen, u.v.a.m.

Hier der einleitende Text zur Papierform der Umfrage:
Das Experiment zur CEBIT11.-14.7.2018 – von Prof. Adrian Müller, HS KL
Sehr geehrte Zuhörerinnen und Zuhörer,
wir freuen uns sehr über Ihr Interesse am Thema! Wir laden Sie herzlich ein, an unserem kurzen Experiment teilzunehmen: Können Sie vorhersagen, wo die sprachlichen Grenzen der heutigen sprach-basierten Assistenten liegen? Schätzen Sie Amazons „Alexa“ und Googles „Asistenten“ ein!
Würden die Probanden die Antworten und die Grenzen des Systems einschätzen können? Würden Sie eine konsistente Einschätzung abgeben, oder würden Sie an der ein oder anderen Stelle schlichtweg raten müssen, wie sich ihre „KI“ verhält?
Hier Beispiele aus dem Bereich „Textverständnis und Semantik“, mit einem „x“ beim tatsächlichen Systemverhalten („Ja“ bedeutet: die Frage wird verstanden und beantwortet, bzw. die Aktion kann ausgeführt werden).
Hätten Sie es gewusst?
| Textverständnis und Semantik | Ja | Evtl. | Nein |
| Alexa: Wer ist Angela Merkel? | x | ||
| Alexa: Wer ist seit 2005 amtierende Bundeskanzlerin von Deutschland? | x | ||
| OK Google: Wer ist Jean Claude Juncker? | x | ||
| OK Google: Wer ist der Präsident der Europäischen Kommission? | x | ||
| Alexa: Mache das Licht im Büro an! | x | ||
| Alexa: Mache das Licht im Büro nicht an! | x |
Das Ergebnis war eindeutig. Zwar waren die Vorhersagen bei den einfachen Einstiegsfragen in den unterschiedlichen Bereichen konsistent und weitestgehend korrekt. In der Grafik 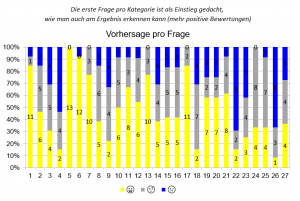 sind dies die Fragen 1,5, 13,17, und 22.
sind dies die Fragen 1,5, 13,17, und 22.
Jedoch sowohl die Streuung, als auch die intersubjektive Korrelation bei den nicht-trivialen Tests zeigen, dass die Probanden an vielen Stellen raten mussten.
Problematisch an diesem Nicht-Verstehen der KI ist, dass dies nicht allen Nutzern bewusst ist, und dass die Hersteller solcher Systeme desungeachtet sicherheitsrelevante oder kritische medizinische Anwendungen („Notdienst anrufen“) auf Basis dieses sehr einfachen Sprachmodells planen oder teilweise bereits anbieten.
Den gleichen Test hatten wir im März 2018 im Rahmen eines Vortrags über sprach-basierte Assistenten schon einmal durchgeführt, mit den gleichen Ergebnissen. Diese Reaktion der Nicht-Fachleute führte zu einer Diskussion über die – angebliche – Intelligenz von Chat-Bots, sprach-basierten Assistenten und sprach-verstehenden Systemen. Die Meinungen dazu finden Sie hier in einem weiteren „Standpunkt“ – Beitrag des Arbeitskreises Smart-Machines.
Bewusstsein ohne Körper?
Anfang 2014 schauten die Roboterenthusiasten der ganzen Welt gebannt auf eine Ankündigung der Firma KUKA. Die Pressemitteilungen waren so unklar formuliert, dass viele von einer live Veranstaltung ausgingen:
„An diesem Dienstag sollte es in Shanghai zum ultimativen Showdown zwischen Mensch und Maschine kommen. Auf der einen Seite des ungewöhnlichsten Tischtennismatches der Welt sollte der sechsfache Europameister und Weltklassespieler Timo Boll stehen – 1,81 Meter groß, 78 Kilogramm schwer, 33 Jahre alt. Auf der anderen Seite Kuka KR Agilus, der schnellste Roboterarm der Welt, ausgestattet mit sechs Achsen, einer Reichweite von fast einem Meter und einer Bewegungspräzision von 0,03 Millimetern.“
Quelle: Ingenieur.de
Einer der effizientesten Industrieroboter, der Agilus, im Kampf gegen einen der besten Tischtennisspieler der Welt, Timo Boll. Als es statt des erhofften Live-Duells zu einer Videopräsentation kam hat das die Begeisterung kaum gedämpft. Damals – und interessanterweise heute immer noch – fanden sich viele Blog-Beiträge die der Performance des Agilus Respekt zollten.



Was man auf den nachstehenden Fotos nur erahnen kann zeigt das Video unter https://www.youtube.com/watch?v=tIIJME8-au8 . Schnelle Ballwechsel, voller Körpereinsatz, hohe Beweglichkeit und im Laufe des Matches immer stärkere Tricks, Netzroller, Spins und andere Techniken des Profis wurden vom Roboter ebenbürtig erwidert. Ist es technisch möglich?
Die Antwort lautet nein. Es war ein montiertes Werbevideo, ein fake. Gedreht 2014, in Sofia, Bulgarien.
„Im Werbevideo duelliert sich Boll mit dem Roboterarm. Alles wirkt spontan und echt. Kuka bestätigte allerdings gegenüber Ingenieur.de, dass das Spiel programmiert war. Ein völlig freies Match sei erst in ein paar Jahren denkbar.“
Quelle: Ingenieur.de
Wo liegen die Probleme bei der Programmierung eines solchen Roboters? Es gibt Stimmen die sagen, ein Roboter kann keine wirkliche Intelligenz entwickeln, da er nie ein Kind war. Wenn Sie sich das Beispiel eines Kleinkindes anschauen wissen Sie was das meint. Die Auge-Hand Koordination, die Berechnung der Geschwindigkeit, des Impulses des Luftwiderstandes – all diese Parameter bringt man Kindern in langsamen, und vorsichtig geworfenen Ballwürfen bei. Das kindliche Gehirn bildet die erforderlichen Engramme aus, um diese hochkomplexen Berechnungen in Echtzeit ausführen zu können. Der Weg von diesem Punkt bis zum Tischtennisweltmeister erfordert weiterhin jahrelanges Training.
Auf dem Niveau eines Timo Boll kommt noch etwas hinzu. Es ist die Fähigkeit, den Schlag des Gegners einzuschätzen, sicher seine Spielweise einzustellen, den Spin anhand der Körperhaltung zu antizipieren. Von der reinen Flugbewegung des Balles erhält eine Stereo Kamera nicht genügend Information. Der Zeitpunkt vom Aufprall auf der Platte bis zur Reaktion ist für heutige technische Systeme und für die über 50 kg schwere Mechanik eines Roboterarms in der Tat noch zu kurz. D. h., entweder kann der Roboter die Körpersprache seines Gegners lesen, und dann auch noch Körpertäuschungen und Finten erkennen, oder wird eine zu hohe Fehlerquote haben um mit dieser Präzision und diesem Effet geschlagenen Bällen begegnen zu können.
Für Interessierte findet sich das „Making-of“ unter https://www.youtube.com/watch?v=c2NeW9o5G6s.
Das bedeutet nicht, dass eine Maschine nicht in der Lage ist ein genetisches System wie ein Tischtennisball nicht zu erlernen.


Das Verfahren, dass die TU Darmstadt und das Max-Planck-Institut angewandt haben, basiert auf Versuch und Irrtum, lernt aber unterschiedlich im Vergleich zu einem Kind. Die Basis sind die Bewegungs-Primitiven des verwendeten Roboter-Arms:
Learning new motor tasks from physical interactions is an important goal for both robotics and machine learning. However, when moving beyond basic skills, most monolithic machine learning approaches fail to scale. For more complex skills, methods that are tailored for the domain of skill learning are needed. In this paper, we take the task of learning table tennis as an example and present a new framework that allows a robot to learn cooperative table tennis from physical interaction with a human. The robot learns a set of elementary table tennis hitting movements from a human table tennis teacher by kinesthetic teach-in, which is compiled into a set of motor primitives represented by dynamical systems. The robot subsequently generalizes these movements to a wider range of situations using our mixture of motor primitives approach. The resulting policy enables the robot to select appropriate motor primitives as well as to generalize between them. Finally, the robot plays with a human table tennis partner and learns online to improve its behavior. We show that the resulting setup is capable of playing table tennis using an anthropomorphic robot arm.
Quelle: Learning to select and generalize striking movements in robot table tennis (2012) , by Jens Kober , Oliver Kroemer , Jan Peters Venue: In Proceedings of the AAAI 2012 Fall Symposium on robots that Learn Interactively from Human Teachers
Das Video des wirklich Tischtennis-spielenden Roboterarms finden Sie unter Towards Learning Robot Table Tennis.
Industrie 4.0 – worauf man als Informatiker achten sollte
Im Produktionsumfeld von Industrie 4.0 Anlagen werden Roboter zunehmend flexibler, und sie interagieren stärker mit Menschen als bisher, als sich ihre einfacheren Vorgänger noch in Sicherheitskäfigen und abgegrenzten Bereichen befanden.
Diese „Co-Bots“ bringen Partnerschaft in Mensch-Maschine-Teams, Entlastung bei riskanten Tätigkeiten, und sind Sicher durch „intelligentes“ Verhalten. Dabei müssen sie flexibel und lernfähig sein, damit sie überall einsetzbar sind.
Wie sicher ist diese neue Arbeitswelt? Spielt Stress eine signifikante Rolle? So müssen Mitarbeiter innerhalb einer gewissen Zeit beispielsweise eine bestimmte Stückzahl erfüllen. Doch was wenn der kooperativ zuarbeitende Roboter Fehler macht?
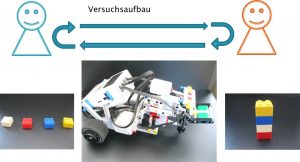
Versuchsaufbau: Bringen Sie möglichst viele Klötzchen von links nach rechts. Der Bot wird sie transportieren.
Vladmir Albach, Student Master Informatik, hat im Studienfach „Wissenschaftliche Kommunikation“, Master Informatik, 2017 ein Experiment dazu durchgeführt.
In der Programmierung für den Roboter wurden Absichtlich zu einem frühen Zeitpunkt wiederkehrende Ablauf-Störungen eingebaut, die für alle Probanden im Ablauf gleich waren. So konnte der Roboter vor Ankunft an seinem Ziel die Steine abwerfen oder zwischendrin kurz stehen bleiben.
Das Experiment wurde mit insgesamt 10 Probanden durchgeführt. Von diesen 10 Probanden hatten vier Probanden erhöhte Kenntnisse aus dem Bereich der künstlichen Intelligenz.
Das Experiment dauerte fünf Minuten. Dabei wurden die Probanden zufällig, aber gleich verteilt in zwei Gruppen eingeteilt. Somit gab es jeweils drei Probanden ohne und zwei mit erhöhten Kenntnissen in jeder Gruppe.
Die Versuchsgruppe, die unter Stress gesetzt wurde, sollte in den fünf Minuten 20 Türme bauen und von dem Roboter über eine Strecke von 2 Metern transportieren lassen. Durch die Ablaufstörungen wurde der Stresseffekt verstärkt. Die Kontrollgruppe bekam dieselbe Aufgabe, nur ohne die Vorgabe 20 Türme bauen zu müssen.
Quelle: Die vollständige Studie mit allen Ergebnissen finden Sie hier auf meiner Homepage der Hochschule.
Neue Arbeitsformen durch KI: High-Speed Science
Im Beitrag “Sergey Brin’s Search for a Parkinson’s Cure” berichtet das Magazin WIRED von einer bemerkenswerten Doublette in der wissenschaftlichen Forschung vor wenigen Jahren:
Can a model fueled by data sets and computational power compete with the gold standard of research? Maybe: Here are two timelines—one from an esteemed traditional research project run by the NIH, the other from the 23andMe Parkinson’s Genetics Initiative. They reached almost the same conclusion about a possible association between Gaucher’s disease and Parkinson’s disease, but the 23andMe project took a fraction of the time.—Rachel Swaby
Traditional Model
- Hypothesis: An early study suggests that patients with Gaucher’s disease (caused by a mutation to the GBA gene) might be at increased risk of Parkinson’s.
- Studies: Researchers conduct further studies, with varying statistical significance.
- Data aggregation: Sixteen centers pool information on more than 5,500 Parkinson’s patients.
- Analysis: A statistician crunches the numbers.
- Writing: A paper is drafted and approved by 64 authors.
- Submission: The paper is submitted to The New England Journal of Medicine. Peer review ensues.
- Acceptance: NEJM accepts the paper.
- Publication: The paper notes that people with Parkinson’s are 5.4 times more likely to carry the GBA mutation.
Total time elapsed: 6 years
Parkinson’s Genetics initiative
- Tool Construction: Survey designers build the questionnaire that patients will use to report symptoms.
- Recruitment: The community is announced, with a goal of recruiting 10,000 subjects with Parkinson’s.
- Data aggregation: Community members get their DNA analyzed. They also fill out surveys.
- Analysis: Reacting to the NEJM paper, 23andMe researchers run a database query based on 3,200 subjects. The results are returned in 20 minutes.
- Presentation: The results are reported at a Royal Society of Medicine meeting in London: People with GBA are 5 times more likely to have Parkinson’s, which is squarely in line with the NEJM paper. The finding will possibly be published at a later date.
Total time elapsed: 8 months
Quelle: Wired.com
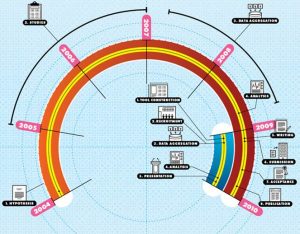
Speed Science: die Grafik zeigt den zeitlichen Ablauf beider Studien. Quelle: https://www.wired.com/2010/06/ff-sergeys-search/
Ein anderes Beispiel für Innovation durch Mining und KI waren die https://en.wikipedia.org/wiki/Google_Flu_Trends
In computer science, the process of mining such large data sets for useful associations is known as a market-basket analysis. Conventionally, it has been used to divine patterns in retail purchases. It’s how Amazon.com can tell you that „customers who bought X also bought Y.“
This computing power can be put to work to answer questions about health. As an example, Brin cites a project developed at his company’s nonprofit research arm, Google.org
Google Flu Trends, the idea is elegantly simple: Monitor the search terms people enter on Google, and pull out those words and phrases that might be related to symptoms or signs of influenza, particularly swine flu.
Das Vorhersage-System ist zwischenzeitlich eingestellt worden. Hier eine Grafik aus 2014/15:
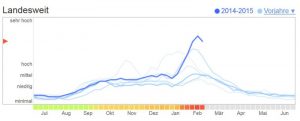
Suchanfragen nach grippe-relevanten Begriffen in den letzten 6 Jahren und das aktuelle Jahr (2014/15) in dick-blau. Die anderen Jahre sind jeweils schwächer blau hinterlegt
Damit kann das Robert-Koch Institut viel früher Warnungen herausgeben und Impfungen planen, als wenn auf die Berichte der Ärzte und Krankenhäuser gewarten werden muss; erneut ein wichtiger Zeitgewinn durch neue Methoden der KI und des Text Minings.
Die Zusammenfassung
- Was KI kann – wenn man es richtig macht
- Planen, Muster erkennen, Vorhersagen berechnen, usw. – wenn Daten, Lernverfahren und intendiertes Modell aufeinander abgestimmt sind
- Exploratives Arbeiten im Zusammenspiel mit dem Menschen unterstützen
- Was KI nicht kann – jedenfalls nicht die uns bekannten Ansätze
- Robustheit garantieren
- Erwartungshaltung der Anwender überwinden
- Menschliche Sprache, Dialoge und Körperlichkeit
Hoffentlich konnte dieser Beitrag einige der übertriebenen Erwartungen, und einige der übersehenen Chancen der Künstlichen Intelligenz für unterschiedliche Leser-Gruppen nachvollziehbar darstellen.
Weitere Projekte, Argumente und einen Austausch zum Thema finden Sie auf der Homepage des Arbeitskreises Smart Machines der Hochschule Kaiserslautern, https://smart-machines.hs-kl.de/. Wir freuen uns auf Ihre Kommentare.
Ihr
Adrian Müller
Projektleitung AK Smart-Machines
August 2018
Danke an Thomas Schmidt für die fachliche Überprüfung.